概要
Cloudflare Pagesでrobots.txtを置いているのに、AIクローラー側ではDisallow扱いになる場合、ファイルそのものではなくCloudflare側のAI Crawl Controlが原因になっていることがあります。
Cloudflare Pagesで静的サイトを運用している場合、robots.txtをGitHub上に配置すれば、その内容がそのまま公開されるように見えます。通常であれば、ルート直下にrobots.txtを置き、Cloudflare Pagesにデプロイすれば、ブラウザから確認できるはずです。
しかし実務では、ブラウザで見えているrobots.txtと、AIクローラー側で判定されているrobots.txtが一致しないケースがあります。
今回確認したのは、Google SitesとCloudflare Pagesを組み合わせた構成で、robots.txtを更新したにもかかわらず、AIクローラー側ではDisallowが解除されないという現象です。原因はGoogle Sites側でもGitHub側でもなく、Cloudflare AI Crawl Controlの「Managed robots.txt」機能でした。
発生していた症状
今回の状態は、一見するとかなり分かりにくいものでした。ブラウザからrobots.txtを見ると問題がなさそうに見える一方で、Cloudflare側のAIクローラー判定ではブロックされているように見えていたためです。
- robots.txtを書き換えても反映されない
- GPTBotがブロック扱いになる
- ChatGPT-Userが取得できない
- Cloudflare Radar上ではDisallow表示になる
- ブラウザでrobots.txtを見るとAllowになっている
- sitemap.xmlは正常に表示されている
- Cloudflare Pagesのデプロイも正常
- Google Sites側にも問題が見当たらない
つまり、人間がブラウザで確認している結果と、AIクローラーに対する制御結果が一致していない状態でした。このような症状では、最初にGitHub上のファイル、Pagesのビルド、ルーティング設定を疑いたくなります。
原因
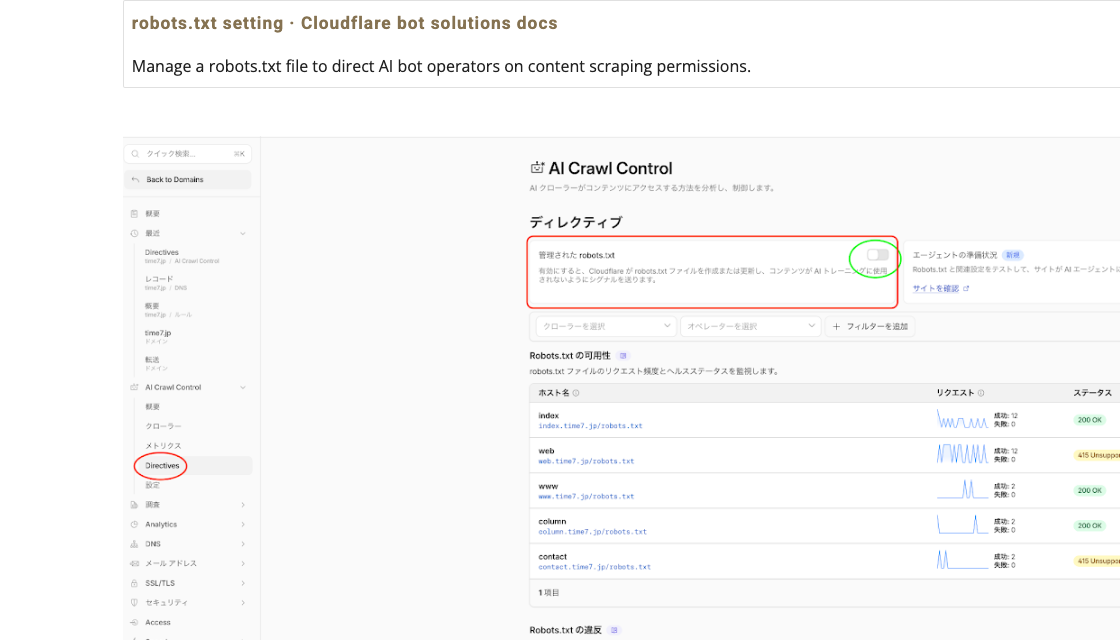
原因は、Cloudflare AI Crawl ControlのManaged robots.txtが有効になっていたことです。
この機能が有効になっていると、Cloudflare側がAI bot向けのrobots.txtを自動生成・管理します。その結果、GitHub上に置いたrobots.txtや、Cloudflare Pages上で配信しているrobots.txtとは別に、Cloudflare側の制御が優先される場合があります。
今回のケースでは、Cloudflare側で以下のようなAIクローラー向けの指示が生成されていました。
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: ClaudeBot
Disallow: /つまり、GitHub上のrobots.txtやCloudflare Pages上のrobots.txtをいくら修正しても、AIクローラー向けにはCloudflare側のManaged robots.txtが影響していたということです。
なぜ気づきにくいのか
この問題が厄介なのは、通常のブラウザ確認だけでは異常に気づきにくい点です。
例えば、ブラウザで https://column.time7.jp/robots.txt を開くと、Allowになっているように見えます。ところがAIクローラー向けには、Cloudflare内部で別の制御が働いている場合があります。
- 人間が見るrobots.txt
- AIクローラーが解釈するrobots.txt
- Cloudflare側で管理されているAI bot向け制御
これらが必ずしも同じ結果になるとは限りません。Cloudflareは便利な反面、Pages、Workers、DNS、Bot管理、AI Crawl Controlなど複数のレイヤーが存在します。そのため、どのレイヤーが最終的なレスポンスや判定に影響しているかを確認する必要があります。
実際の解決方法
今回のケースでは、Cloudflare管理画面でAI Crawl Controlの設定を確認し、Managed robots.txtをOFFにすることで解決しました。
- Cloudflare管理画面を開く
- 対象ドメインを選択する
- AI Crawl Controlを確認する
- Directivesを開く
- Managed robots.txtをOFFにする
- 再度robots.txtとクローラー判定を確認する
設定変更後、robots.txtの応答が200 OKとなり、Allowの内容が正常に反映されました。重要なのは、コードだけでなくCloudflare管理画面側の自動制御も確認することです。
実際に使用したrobots.txt
現在は、まず意図を分かりやすくするため、シンプルなrobots.txt構成にしています。
User-agent: *
Allow: /
Sitemap: https://column.time7.jp/sitemap.xmlrobots.txtは、複雑に書けば良いというものではありません。特に検証中は、何を許可し、どのサイトマップを見せたいのかを明確にすることが大切です。
Google Sites単体では難しい点
Google Sitesは、ページ公開や簡易サイト運用には非常に便利です。一方で、SEOやAIクローラー制御まで含めて細かく設計するには制限があります。
- robots.txt制御
- sitemap.xml制御
- AIクローラー制御
- canonical制御
- 独自HTML index
- リダイレクト制御
そのため、Google Sitesをコンテンツ管理側として使い、Cloudflare Pagesでindexやsitemapを補完する構成は、実務上かなり有効です。
なぜこの構成が重要なのか
現在の検索環境は、Google検索だけを前提にすればよい時代ではありません。ChatGPT、Gemini、Claude、Perplexity、Bing Copilotなど、AIがWeb上の情報を取得し、回答生成に利用する場面が増えています。
そのため、Webサイト運用では、検索エンジンだけでなくAIクローラーに対しても、どの情報を読ませるのか、どのURLを案内するのかを意識する必要があります。
- robots.txt
- sitemap.xml
- HTML構造
- 独自ドメイン
- 内部リンク
- Cloudflare側のAI関連設定
これらは、単なる技術設定ではなく、Web上で情報をどう発見されるかを決める設計要素になっています。
実務上の注意点
Cloudflareは、DNS、Pages、Workers、WAF、Bot管理、AI関連機能などをまとめて扱える強力なサービスです。ただし、機能が多い分、意図しない設定が別レイヤーで効いていることがあります。
- GitHub上のrobots.txtだけを見て判断しない
- Cloudflare Pagesのデプロイ結果を確認する
- WorkersやRoutesの有無を確認する
- AI Crawl ControlのManaged robots.txtを確認する
- Cloudflare Radarや各種クローラー判定も確認する
- 設定変更後はキャッシュや反映時間も考慮する
特に「robots.txtを書いたのに効かない」という場合は、ファイルそのものよりも、Cloudflare側で上書き・補完・自動生成されていないかを確認した方が早いことがあります。
Time合同会社での活用
Time合同会社では、Cloudflareを単なるCDNや高速化ツールではなく、Web制御レイヤーとして活用しています。
Google Sites、Cloudflare Pages、Google Workspace、AppSheet、生成AIを組み合わせることで、低コストで運用しやすいWeb構成を作りながら、SEOやAI検索、問い合わせ導線、更新運用まで含めた実務設計を行っています。
- SEO
- AI検索
- 問い合わせ導線
- 更新運用
- DX
- Cloudflareによる制御設計
今回のrobots.txtのような問題は、コードだけを見ていても気づきにくいものです。実務では、GitHub、Cloudflare、ブラウザ表示、クローラー判定を横断して確認する視点が重要です。
まとめ
Cloudflareでrobots.txtが反映されない場合、GitHub上のファイルやCloudflare Pagesのデプロイだけでなく、Cloudflare AI Crawl ControlのManaged robots.txtも確認する必要があります。
ブラウザではAllowに見えていても、AIクローラー向けには別の制御が働いている場合があります。特にCloudflare Pages、Workers、独自ドメイン、AI Crawl Controlを組み合わせる場合は、どのレイヤーが最終的に効いているのかを丁寧に切り分けることが重要です。
robots.txtやsitemap.xmlは、今後のSEOやAI検索対応においてますます重要になります。Cloudflareを使う場合は、便利な自動機能と手動設定の優先関係まで含めて確認しておくと、意図しないブロックやクロール不一致を避けやすくなります。